
Search Exchange
Search All Sites
Nagios Live Webinars
Let our experts show you how Nagios can help your organization.Login
 New Listings
New ListingsDirectory Tree
check_linux_stats Featured
Current Version
1.5
Last Release Date
2015-11-27
Compatible With
- Nagios 2.x
- Nagios 3.x
- Nagios 4.x
- Nagios XI
Owner
License
GPL
Hits
477798
Files:
| File | Description |
|---|---|
| check_linux_stats.pl | check_linux_stats |
| nrpe.cfg.sample | nrpe.cfg.sample |
Meet The New Nagios Core Services Platform
Built on over 25 years of monitoring experience, the Nagios Core Services Platform provides insightful monitoring dashboards, time-saving monitoring wizards, and unmatched ease of use. Use it for free indefinitely.
Monitoring Made Magically Better
- Nagios Core on Overdrive
- Powerful Monitoring Dashboards
- Time-Saving Configuration Wizards
- Open Source Powered Monitoring On Steroids
- And So Much More!
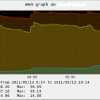
A perl plugin using Sys::Statistics::Linux
Thanks to Jonny Schulz, the author of Sys::Statistics::Linux, for his great work (http://search.cpan.org/~bloonix/) !
v1.2 Changelog :
- Add Paging statistics
- Add swapused and active memory on perfparse statistics
- Remove unused -H option (mthuijs)
v1.3 Changelog :
- Add uptime check, warning threshold in minutes (csterley)
- Replace /usr/local/nagios/libexec with FindBin (eulen)
- Fix reports network traffic in bytes (dbsanders)
v1.4 Changelog :
- Illegal division by zero (helium_rday, RedFish)
- Get the cache out of the used memory (waterdeep, dbsanders)
- Removed unused $return_str on check io disk (RedFish)
- Add steal cpu statistics
v1.5 Changelog :
- Add paging statistics to check for major faults (kevin@candidsource.com)
- bug, when using unit=MB for disk usage, the perf data writtens only KB (john12)
- Bug, multiple pipe on IO perfcournter (ledistordu)
- Add CPU context switch statistics
Usage :
-h, --help
print this help message
-C, --cpu
check cpu usage
-P, --proc
check the processes number
-M, --memory
check memory usage (memory used, swap used and memory cached)
-N, --network=NETWORK USAGE
check network usage in resq or bytes (default bytes)
-D, --disk=DISK USAGE
check disk usage
-I, --io=DISK IO USAGE
check disk I/O (r/w on /dev/sd*)
-L, --load=LOAD AVERAGE
check load average
-F, --file=FILE STATS
check open files (file alloc, inode alloc)
-S, --socket=SOCKET STATS
socket usage (tcp, udp, raw)
-W, --paging=PAGING AND SWAPPING STATS
-X, --ctxt=CPU CONTEXT SWITCH
check CPU context switch
-U, --uptime
-p, --pattern
eth0,eth1...sda1,sda2.../usr,/tmp
-w, --warning
warning thresold
-c, --critical
critical thresold
-s, --sleep
default 1 sec.
-u, --unit
%, KB, MB or GB left on disk usage, default : MB
REQS OR BYTES on disk io statistics, default : REQS
-V, --version
version number
ex :
* Cpu usage :
./check_linux_stats.pl -C -w 90 -c 100 -s 5
CPU OK : idle 99.80% | user=0.00% system=0.20% iowait=0.00% idle=99.80%;90;100
* Load average :
./check_linux_stats.pl -L -w 10,8,5 -c 20,18,15
LOAD AVERAGE OK : 0.20,0.07,0.16 | load1=0.20;10;20;0 load5=0.07;8;18;0 load15=0.16;5;15;0
* Memory usage :
./check_linux_stats.pl -M -w 99,50 -c 100,50
MEMORY OK : Mem used=92.57%, Swap used=0.01% |MemUsed=92.57%;95;99 SwapUsed=0.01;50;50 MemCached=12.62 SwapCached=0.00 Active=12.61
* Disk usage :
./check_linux_stats.pl -D -w 10 -c 5 -p /,/usr,/tmp,/var
DISK WARNING used : / 3331.80MB on 3875.09MB (8.86% free) /usr 10084.27MB on 14528.41MB (25.43% free)| /=3331.80MB /usr=10084.27MB
* Disk I/O :
./check_linux_stats.pl -I -w 100,70 -c 150,100 -p sda1,sda2,sda4
DISK I/O OK | sda2_read=0.00;100;150 sda2_write=0.00;70;100 sda4_read=0.00;100;150 sda4_write=0.00;70;100 sda1_read=0.00;100;150 sda1_write=0.00;70;100
* Network usage :
./check_linux_stats.pl -N -w 30000 -c 45000 -p eth0
NET USAGE OK eth0:8021.78KB | eth0_txbyt=3461.39KB eth0_txerrs=0.00KB eth0_rxbyt=4560.40KB eth0_rxerrs=0.00KB
* Open files :
./check_linux_stats.pl -F -w 10000,150000 -c 15000,250000
OPEN FILES OK allocated: 1728 (inodes: 70390) | fhalloc=1728;10000;15000;411810 inalloc=70390;150000;250000;100250 dentries=50754
* Socket usage :
./check_linux_stats.pl -S -w 1000 -c 2000
SOCKET USAGE OK : used 257 |used=257;1000;2000 tcp=18 udp=5 raw=0
* Number of procs :
./check_linux_stats.pl -P -w 1000 -c 2000
PROCS OK : count 272 |count=272;1000;2000 runqueue=2 blocked=0 running=2 new=0.98
* Process mem & cpu :
./check_linux_stats.pl -T -w 2000000000 -c 3000000000 -p /var/run/jonas.pid
PROCESSES OK | java_vsize=1804918784;2000000000;3000000000 java_nswap=0 java_cnswap=0 java_cpu=0
* Paging statistics :
./check_linux_stats.pl -W -w 10,1000,1 -c 20,2000,20 -s 3
Paging OK : in:0.00,out:0.00,flt:0.00 |pgpgin=0.00;10;20;0 pgpgout=0.00;1000;2000;0 pgmajfault=0.00;1;20;0 pswpin=0.00 pswpout=0.00
* Cpu context switch :
./check_linux_stats.pl -X -w 6000 -c 70000 -s 2
CONTEXT SWITCH OK : context 80|ctxt=80
* Uptime :
./check_linux_stats.pl -U -w 9
WARNING : up 0 days, 00:08:16 |uptime=496.05
-h, --help
print this help message
-C, --cpu
check cpu usage
-P, --proc
check the processes number
-M, --memory
check memory usage (memory used, swap used and memory cached)
-N, --network=NETWORK USAGE
check network usage in resq or bytes (default bytes)
-D, --disk=DISK USAGE
check disk usage
-I, --io=DISK IO USAGE
check disk I/O (r/w on /dev/sd*)
-L, --load=LOAD AVERAGE
check load average
-F, --file=FILE STATS
check open files (file alloc, inode alloc)
-S, --socket=SOCKET STATS
socket usage (tcp, udp, raw)
-W, --paging=PAGING AND SWAPPING STATS
-X, --ctxt=CPU CONTEXT SWITCH
check CPU context switch
-U, --uptime
-p, --pattern
eth0,eth1...sda1,sda2.../usr,/tmp
-w, --warning
warning thresold
-c, --critical
critical thresold
-s, --sleep
default 1 sec.
-u, --unit
%, KB, MB or GB left on disk usage, default : MB
REQS OR BYTES on disk io statistics, default : REQS
-V, --version
version number
ex :
* Cpu usage :
./check_linux_stats.pl -C -w 90 -c 100 -s 5
CPU OK : idle 99.80% | user=0.00% system=0.20% iowait=0.00% idle=99.80%;90;100
* Load average :
./check_linux_stats.pl -L -w 10,8,5 -c 20,18,15
LOAD AVERAGE OK : 0.20,0.07,0.16 | load1=0.20;10;20;0 load5=0.07;8;18;0 load15=0.16;5;15;0
* Memory usage :
./check_linux_stats.pl -M -w 99,50 -c 100,50
MEMORY OK : Mem used=92.57%, Swap used=0.01% |MemUsed=92.57%;95;99 SwapUsed=0.01;50;50 MemCached=12.62 SwapCached=0.00 Active=12.61
* Disk usage :
./check_linux_stats.pl -D -w 10 -c 5 -p /,/usr,/tmp,/var
DISK WARNING used : / 3331.80MB on 3875.09MB (8.86% free) /usr 10084.27MB on 14528.41MB (25.43% free)| /=3331.80MB /usr=10084.27MB
* Disk I/O :
./check_linux_stats.pl -I -w 100,70 -c 150,100 -p sda1,sda2,sda4
DISK I/O OK | sda2_read=0.00;100;150 sda2_write=0.00;70;100 sda4_read=0.00;100;150 sda4_write=0.00;70;100 sda1_read=0.00;100;150 sda1_write=0.00;70;100
* Network usage :
./check_linux_stats.pl -N -w 30000 -c 45000 -p eth0
NET USAGE OK eth0:8021.78KB | eth0_txbyt=3461.39KB eth0_txerrs=0.00KB eth0_rxbyt=4560.40KB eth0_rxerrs=0.00KB
* Open files :
./check_linux_stats.pl -F -w 10000,150000 -c 15000,250000
OPEN FILES OK allocated: 1728 (inodes: 70390) | fhalloc=1728;10000;15000;411810 inalloc=70390;150000;250000;100250 dentries=50754
* Socket usage :
./check_linux_stats.pl -S -w 1000 -c 2000
SOCKET USAGE OK : used 257 |used=257;1000;2000 tcp=18 udp=5 raw=0
* Number of procs :
./check_linux_stats.pl -P -w 1000 -c 2000
PROCS OK : count 272 |count=272;1000;2000 runqueue=2 blocked=0 running=2 new=0.98
* Process mem & cpu :
./check_linux_stats.pl -T -w 2000000000 -c 3000000000 -p /var/run/jonas.pid
PROCESSES OK | java_vsize=1804918784;2000000000;3000000000 java_nswap=0 java_cnswap=0 java_cpu=0
* Paging statistics :
./check_linux_stats.pl -W -w 10,1000,1 -c 20,2000,20 -s 3
Paging OK : in:0.00,out:0.00,flt:0.00 |pgpgin=0.00;10;20;0 pgpgout=0.00;1000;2000;0 pgmajfault=0.00;1;20;0 pswpin=0.00 pswpout=0.00
* Cpu context switch :
./check_linux_stats.pl -X -w 6000 -c 70000 -s 2
CONTEXT SWITCH OK : context 80|ctxt=80
* Uptime :
./check_linux_stats.pl -U -w 9
WARNING : up 0 days, 00:08:16 |uptime=496.05
Reviews (49)
bypbhardwaj, July 1, 2020
Hi Team ,
I am new in linux and using nagios , I want to understand what are these parameters works with this scripts .
/usr/local/nagios/libexec/check_linux_stats.pl -M -w 99,50 -c 100,50
What is the meaning of -w 99,50 and -c 100,50 . What are these values .
Please help me to understand it in memory script .
Regards
Parshant Bhardwaj
I am new in linux and using nagios , I want to understand what are these parameters works with this scripts .
/usr/local/nagios/libexec/check_linux_stats.pl -M -w 99,50 -c 100,50
What is the meaning of -w 99,50 and -c 100,50 . What are these values .
Please help me to understand it in memory script .
Regards
Parshant Bhardwaj
bymouseymars, May 26, 2020
Nice little collection.
Is there a set of pnp4nagios templates for it?
Is there a set of pnp4nagios templates for it?
byapsivam, July 11, 2018
I have made some changes to this plugin at https://github.com/apsivam/monitoring_plugins/blob/master/check_linux_stats.pl.
How can I submit PR?
My changes:
*) percentage based check for disk usage will return percentage perfdata instead of KB
*) added an option to exclude file systems types for disk usage check so that we can exclude file systems like tmpfs, devtmpfs, etc.
How can I submit PR?
My changes:
*) percentage based check for disk usage will return percentage perfdata instead of KB
*) added an option to exclude file systems types for disk usage check so that we can exclude file systems like tmpfs, devtmpfs, etc.
bysam20, April 11, 2017
Hi,
Great work.
I am fairly new to linux and nagios. But is there a tutorial/Link to import and run a plugin?
Thanks in advance!
Great work.
I am fairly new to linux and nagios. But is there a tutorial/Link to import and run a plugin?
Thanks in advance!
Congratulations for the plugin. I like a lot, but it seems to have problems to execute NRPE, as when I run this plugin with NRPE it is unable to read the output. I have seen that other people have the same error. Could you help us to execute this plugin in remote? I have configured it, but it doen't work.
byshamimreza, August 6, 2016
The plugins is great.. working with everything really fine but while i am using the unit variable with MB for Network Usages then its showing the default KB value.
byunassassinable, May 3, 2016
Works great!
bymhoogveld, April 16, 2016
I really like this plugin and have written an extension which I'd like to send to you.
However, I can't seem to reach the owner by email at plugmon@free.fr
I get a "550 5.2.1 This mailbox has been blocked due to inactivity" error message.
How can the owner be reached?
However, I can't seem to reach the owner by email at plugmon@free.fr
I get a "550 5.2.1 This mailbox has been blocked due to inactivity" error message.
How can the owner be reached?
byifcnet, March 4, 2016
Hi!,This plugin is great i can do a lot of things with only one command,thanks to the developer.
In the shell all works fine,but i can't show it in the WEB-GUI(Of course before that I added the plugin to the nrpe.cfg and reload the nagios service.)
Whats is the problem here?
Thanks a lot for your support.
In the shell all works fine,but i can't show it in the WEB-GUI(Of course before that I added the plugin to the nrpe.cfg and reload the nagios service.)
Whats is the problem here?
Thanks a lot for your support.
byBarreto, January 27, 2016
Check CPU is presenting problem, does anyone know what they have to modify the script?
/usr/lib64/nagios/plugins/check_linux_stats.pl -C -w 90 -c 95
CPU OK : idle 99.50% |idle=99.50%;90;95 user=0.00% system=0.00% iowait=0.50% steal=0.00%check_linux_stats v1.5
Usage: /usr/lib64/nagios/plugins/check_linux_stats.pl -C|-P|-M|-N|-D|-I|-L|-F|-S|-W|-U -p -w -c [-s ] [-u ] [-V] [-h]
-h, --help
print this help message
-C, --cpu=CPU USAGE
-P, --procs
-M, --memory=MEMORY USAGE
-N, --network=NETWORK USAGE
-D, --disk=DISK USAGE
-I, --io=DISK IO USAGE
-L, --load=LOAD AVERAGE
-F, --file=FILE STATS
-S, --socket=SOCKET STATS
-W, --paging=PAGING AND SWAPPING STATS
-X, --ctxt=CPU CONTEXT SWITCH
-U, --uptime
-p, --pattern
eth0,eth1...sda1,sda2.../usr,/tmp
-w, --warning
-c, --critical
-s, --sleep
-u, --unit
%, KB, MB or GB left on disk usage, default : MB
REQS OR BYTES on disk io statistics, default : REQS
-V, --version
version number
ex :
Memory usage : perl check_linux_stats.pl -M -w 90 -c 95
Cpu usage : perl check_linux_stats.pl -C -w 90 -c 95 -s 5
Disk usage : perl check_linux_stats.pl -D -w 95 -c 100 -u % -p /tmp,/usr,/var
Load average : perl check_linux_stats.pl -L -w 10,8,5 -c 20,18,15
Paging statistics : perl check_linux_stats.pl -W -w 10,1000,1 -c 20,2000,20 -s 3
Process statistics : perl check_linux_stats.pl -P -w 100 -c 200
I/O statistics on disk device : perl check_linux_stats.pl -I -w 10 -c 5 -p sda1,sda4,sda5,sda6
Network usage : perl check_linux_stats.pl -N -w 10000 -c 100000000 -p eth0
Processes virtual memory : perl check_linux_stats.pl -T -w 9551820 -c 9551890 -p /var/run/sendmail.pid
Cpu context switch : perl check_linux_stats.pl -X -w 6000 -c 70000 -s 2
Uptime : perl check_linux_stats.pl -U -w 5
/usr/lib64/nagios/plugins/check_linux_stats.pl -C -w 90 -c 95
CPU OK : idle 99.50% |idle=99.50%;90;95 user=0.00% system=0.00% iowait=0.50% steal=0.00%check_linux_stats v1.5
Usage: /usr/lib64/nagios/plugins/check_linux_stats.pl -C|-P|-M|-N|-D|-I|-L|-F|-S|-W|-U -p -w -c [-s ] [-u ] [-V] [-h]
-h, --help
print this help message
-C, --cpu=CPU USAGE
-P, --procs
-M, --memory=MEMORY USAGE
-N, --network=NETWORK USAGE
-D, --disk=DISK USAGE
-I, --io=DISK IO USAGE
-L, --load=LOAD AVERAGE
-F, --file=FILE STATS
-S, --socket=SOCKET STATS
-W, --paging=PAGING AND SWAPPING STATS
-X, --ctxt=CPU CONTEXT SWITCH
-U, --uptime
-p, --pattern
eth0,eth1...sda1,sda2.../usr,/tmp
-w, --warning
-c, --critical
-s, --sleep
-u, --unit
%, KB, MB or GB left on disk usage, default : MB
REQS OR BYTES on disk io statistics, default : REQS
-V, --version
version number
ex :
Memory usage : perl check_linux_stats.pl -M -w 90 -c 95
Cpu usage : perl check_linux_stats.pl -C -w 90 -c 95 -s 5
Disk usage : perl check_linux_stats.pl -D -w 95 -c 100 -u % -p /tmp,/usr,/var
Load average : perl check_linux_stats.pl -L -w 10,8,5 -c 20,18,15
Paging statistics : perl check_linux_stats.pl -W -w 10,1000,1 -c 20,2000,20 -s 3
Process statistics : perl check_linux_stats.pl -P -w 100 -c 200
I/O statistics on disk device : perl check_linux_stats.pl -I -w 10 -c 5 -p sda1,sda4,sda5,sda6
Network usage : perl check_linux_stats.pl -N -w 10000 -c 100000000 -p eth0
Processes virtual memory : perl check_linux_stats.pl -T -w 9551820 -c 9551890 -p /var/run/sendmail.pid
Cpu context switch : perl check_linux_stats.pl -X -w 6000 -c 70000 -s 2
Uptime : perl check_linux_stats.pl -U -w 5
Hi,
There's a small bug in v1.5 on line 62:
"if" should be "elsif" otherwise the -C (check_cpu) option will always show help.
Here's the diff:
--- /usr/lib/nagios/plugins/check_linux_stats.pl.org 2016-01-12 11:51:20.586228411 +0100
+++ /usr/lib/nagios/plugins/check_linux_stats.pl 2016-01-12 11:49:45.223925210 +0100
@@ -59,7 +59,7 @@
if($o_cpu){
check_cpu();
}
-if($o_context){
+elsif($o_context){
check_context_switch();
}
elsif($o_mem){
There's a small bug in v1.5 on line 62:
"if" should be "elsif" otherwise the -C (check_cpu) option will always show help.
Here's the diff:
--- /usr/lib/nagios/plugins/check_linux_stats.pl.org 2016-01-12 11:51:20.586228411 +0100
+++ /usr/lib/nagios/plugins/check_linux_stats.pl 2016-01-12 11:49:45.223925210 +0100
@@ -59,7 +59,7 @@
if($o_cpu){
check_cpu();
}
-if($o_context){
+elsif($o_context){
check_context_switch();
}
elsif($o_mem){
Owner's reply
I fixed this ugly bug..
byemarginated, January 7, 2016
Hello,
great check.
I've found a little bug using hte CPU count.
It show me , on the perfdata, the entire help screen, just after the steal percentage:
[root@ph742502]/usr/local/nagios/libexec# ./check_linux_stats.pl -C -w 70 -c 100 -s 2
CPU OK : idle 91.85 |idle=91.85%;70;100 user=0.59% system=0.34% iowait=7.12% steal=0.00%check_linux_stats v1.5
Usage: ./check_linux_stats.pl -C|-P|-M|-N|-D|-I|-L|-F|-S|-W|-U -p -w -c [-s ] [-u ] [-V] [-h]
-h, --help
print this help message
-C, --cpu=CPU USAGE
-P, --procs
-M, --memory=MEMORY USAGE
Could be possible to solve?
i was not able to find it on the check_cpu section, it looks ok to me (but i'm not a programmer).
Thank you.
Michele
great check.
I've found a little bug using hte CPU count.
It show me , on the perfdata, the entire help screen, just after the steal percentage:
[root@ph742502]/usr/local/nagios/libexec# ./check_linux_stats.pl -C -w 70 -c 100 -s 2
CPU OK : idle 91.85 |idle=91.85%;70;100 user=0.59% system=0.34% iowait=7.12% steal=0.00%check_linux_stats v1.5
Usage: ./check_linux_stats.pl -C|-P|-M|-N|-D|-I|-L|-F|-S|-W|-U -p -w -c [-s ] [-u ] [-V] [-h]
-h, --help
print this help message
-C, --cpu=CPU USAGE
-P, --procs
-M, --memory=MEMORY USAGE
Could be possible to solve?
i was not able to find it on the check_cpu section, it looks ok to me (but i'm not a programmer).
Thank you.
Michele
Owner's reply
I fixed this ugly bug..
Very good plugin.
Last version 1.5
check_cpu should be followed by a elsif.
--- check_linux_stats.pl.old 2016-01-06 22:06:17.000000000 +0100
+++ check_linux_stats.pl 2016-01-06 22:03:33.582324204 +0100
@@ -59,7 +59,7 @@
if($o_cpu){
check_cpu();
}
-if($o_context){
+elsif($o_context){
check_context_switch();
}
elsif($o_mem){
jfr
Last version 1.5
check_cpu should be followed by a elsif.
--- check_linux_stats.pl.old 2016-01-06 22:06:17.000000000 +0100
+++ check_linux_stats.pl 2016-01-06 22:03:33.582324204 +0100
@@ -59,7 +59,7 @@
if($o_cpu){
check_cpu();
}
-if($o_context){
+elsif($o_context){
check_context_switch();
}
elsif($o_mem){
jfr
Owner's reply
I fixed this ugly bug..
Nice plugin. I added a check to paging statistics to check for major faults. diff follows.
--- check_linux_stats.pl 2015-09-11 12:22:42.977785368 -0500
+++ check_linux_stats.pl.orig 2015-08-21 09:11:02.000000000 -0500
@@ -533,22 +533,21 @@
if(defined($stat->pgswstats)) {
$status = "OK";
my $page = $stat->pgswstats;
- my ($warn_in,$warn_out,$warn_flt) = split(/,/,$o_warning);
- my ($crit_in,$crit_out,$crit_flt) = split(/,/,$o_critical);
- if((($page->{pgpgin}>=$crit_in)&&($page->{pgpgout}>=$crit_out))||($page->{pgmajfault}>=$crit_flt)) {
+ my ($warn_in,$warn_out) = split(/,/,$o_warning);
+ my ($crit_in,$crit_out) = split(/,/,$o_critical);
+ if(($page->{pgpgin}>=$crit_in)||($page->{pgpgout}>=$crit_out)) {
$status = "CRITICAL";
}
- elsif((($page->{pgpgin}>=$warn_in)&&($page->{pgpgout}>=$warn_out))||($page->{pgmajfault}>=$warn_flt)) {
+ elsif(($page->{pgpgin}>=$warn_in)||($page->{pgpgout}>=$warn_out)) {
$status = "WARNING";
}
my $perfdata = "|"
."pgpgin=$page->{pgpgin};$warn_in;$crit_in;0 "
."pgpgout=$page->{pgpgout};$warn_out;$crit_out;0 "
- ."pgmajfault=$page->{pgmajfault};$warn_flt;$crit_flt;0 "
."pswpin=$page->{pswpin} pswpout=$page->{pswpout}";
- print "Paging $status : in:$page->{pgpgin},out:$page->{pgpgout},flt:$page->{pgmajfault} $perfdata";
+ print "Paging $status : in:$page->{pgpgin},out:$page->{pgpgout} $perfdata";
}
else {
print "No data";
@@ -627,7 +626,7 @@
Cpu usage : perl check_linux_stats.pl -C -w 90 -c 95 -s 5
Disk usage : perl check_linux_stats.pl -D -w 95 -c 100 -u % -p /tmp,/usr,/var
Load average : perl check_linux_stats.pl -L -w 10,8,5 -c 20,18,15
- Paging statistics : perl check_linux_stats.pl -W -w 10,1000,1 -c 20,2000,20 -s 3
+ Paging statistics : perl check_linux_stats.pl -W -w 10,1000 -c 20,2000 -s 3
Process statistics : perl check_linux_stats.pl -P -w 100 -c 200
I/O statistics on disk device : perl check_linux_stats.pl -I -w 10 -c 5 -p sda1,sda4,sda5,sda6
Network usage : perl check_linux_stats.pl -N -w 10000 -c 100000000 -p eth0
--- check_linux_stats.pl 2015-09-11 12:22:42.977785368 -0500
+++ check_linux_stats.pl.orig 2015-08-21 09:11:02.000000000 -0500
@@ -533,22 +533,21 @@
if(defined($stat->pgswstats)) {
$status = "OK";
my $page = $stat->pgswstats;
- my ($warn_in,$warn_out,$warn_flt) = split(/,/,$o_warning);
- my ($crit_in,$crit_out,$crit_flt) = split(/,/,$o_critical);
- if((($page->{pgpgin}>=$crit_in)&&($page->{pgpgout}>=$crit_out))||($page->{pgmajfault}>=$crit_flt)) {
+ my ($warn_in,$warn_out) = split(/,/,$o_warning);
+ my ($crit_in,$crit_out) = split(/,/,$o_critical);
+ if(($page->{pgpgin}>=$crit_in)||($page->{pgpgout}>=$crit_out)) {
$status = "CRITICAL";
}
- elsif((($page->{pgpgin}>=$warn_in)&&($page->{pgpgout}>=$warn_out))||($page->{pgmajfault}>=$warn_flt)) {
+ elsif(($page->{pgpgin}>=$warn_in)||($page->{pgpgout}>=$warn_out)) {
$status = "WARNING";
}
my $perfdata = "|"
."pgpgin=$page->{pgpgin};$warn_in;$crit_in;0 "
."pgpgout=$page->{pgpgout};$warn_out;$crit_out;0 "
- ."pgmajfault=$page->{pgmajfault};$warn_flt;$crit_flt;0 "
."pswpin=$page->{pswpin} pswpout=$page->{pswpout}";
- print "Paging $status : in:$page->{pgpgin},out:$page->{pgpgout},flt:$page->{pgmajfault} $perfdata";
+ print "Paging $status : in:$page->{pgpgin},out:$page->{pgpgout} $perfdata";
}
else {
print "No data";
@@ -627,7 +626,7 @@
Cpu usage : perl check_linux_stats.pl -C -w 90 -c 95 -s 5
Disk usage : perl check_linux_stats.pl -D -w 95 -c 100 -u % -p /tmp,/usr,/var
Load average : perl check_linux_stats.pl -L -w 10,8,5 -c 20,18,15
- Paging statistics : perl check_linux_stats.pl -W -w 10,1000,1 -c 20,2000,20 -s 3
+ Paging statistics : perl check_linux_stats.pl -W -w 10,1000 -c 20,2000 -s 3
Process statistics : perl check_linux_stats.pl -P -w 100 -c 200
I/O statistics on disk device : perl check_linux_stats.pl -I -w 10 -c 5 -p sda1,sda4,sda5,sda6
Network usage : perl check_linux_stats.pl -N -w 10000 -c 100000000 -p eth0
Owner's reply
Hello,
thanks for your comment,
Ussue fixed on v1.5
byjohn12, June 2, 2015
Hi,
This plugin is indeed superb.
I found a bug that when using unit=MB for disk usage, the perf data writtens only KB.
So to fix, i made changes on line no. 378 from
$perfdata .= " $mountpoint=$usage$o_unit";
To
$perfdata .= " $mountpoint=$tmpusage$o_unit;;;0;$tmptotal";
Addition $tmptotal in perf data will set the max MB in the graph.
Let me know,
regards,
John.
This plugin is indeed superb.
I found a bug that when using unit=MB for disk usage, the perf data writtens only KB.
So to fix, i made changes on line no. 378 from
$perfdata .= " $mountpoint=$usage$o_unit";
To
$perfdata .= " $mountpoint=$tmpusage$o_unit;;;0;$tmptotal";
Addition $tmptotal in perf data will set the max MB in the graph.
Let me know,
regards,
John.
Owner's reply
Hello,
thanks for your comment,
Ussue fixed on v1.5
byledistordu, April 25, 2015
I have a perfcounter problem with 1.4.1 :
/usr/lib/nagios/plugins/check_linux_stats.pl -p sda2,sda5 -I -w 100,70 -c 150,100 [16:04:44]
DISK IO OK |sda2_read=0.00;100;150 sda2_write=0.00;70;100|sda5_read=0.00;100;150 sda5_write=0.00;70;100
Need this result :
DISK IO OK |sda2_read=0.00;100;150 sda2_write=0.00;70;100 sda5_read=0.00;100;150 sda5_write=0.00;70;100
/usr/lib/nagios/plugins/check_linux_stats.pl -p sda2,sda5 -I -w 100,70 -c 150,100 [16:04:44]
DISK IO OK |sda2_read=0.00;100;150 sda2_write=0.00;70;100|sda5_read=0.00;100;150 sda5_write=0.00;70;100
Need this result :
DISK IO OK |sda2_read=0.00;100;150 sda2_write=0.00;70;100 sda5_read=0.00;100;150 sda5_write=0.00;70;100
Owner's reply
Hello,
thanks for your comment,
Ussue fixed on v1.5
I recently tried to email the owner of this plugin however I got the following error:
Google tried to deliver your message, but it was rejected by the server for the recipient domain free.fr by mx1.free.fr. [212.27.48.6].
The error that the other server returned was:
550 5.2.1 This mailbox has been blocked due to inactivity
Google tried to deliver your message, but it was rejected by the server for the recipient domain free.fr by mx1.free.fr. [212.27.48.6].
The error that the other server returned was:
550 5.2.1 This mailbox has been blocked due to inactivity
bymartinboer, January 5, 2015
I ran into 2 really minor issues;
- Sys:Statistics relies on YAML:Syck, but the plugin doesn't complain if that fails.
- the plugin itself does not mention that the -I option needs 2 -w and -c variables.
and I have a small request as well; on virtual machines using lvm you often have a lot of 'disks' attached but most of them are loopback and virtual devices, if you add an option no-fake-disks-for-me-no-sirree (or a shortcut for that), you could loop through the devices in /sys/block/ and use readlink to remove the virtual devices from the list. This saves a lot of output when you don't want to use -p.
- Sys:Statistics relies on YAML:Syck, but the plugin doesn't complain if that fails.
- the plugin itself does not mention that the -I option needs 2 -w and -c variables.
and I have a small request as well; on virtual machines using lvm you often have a lot of 'disks' attached but most of them are loopback and virtual devices, if you add an option no-fake-disks-for-me-no-sirree (or a shortcut for that), you could loop through the devices in /sys/block/ and use readlink to remove the virtual devices from the list. This saves a lot of output when you don't want to use -p.
byedrendar, November 21, 2014
Hi,
First of all, I want to congratulate you on your excellent work with this plugin!
I have a question, I don't understand at all how are obtained the net statistics...
If I check TxBytes in /proc/net/dev to review statistics for bond0, I watch a large number in bytes: 7342573046357
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
bond0:1259548428146 14687025821 0 0 0 0 0 0 7342573046357 15194696711 0 0 0 0 0 0
But, If I check the Nagios web interface, this amount doesn't match with the previous value:
/proc/net/dev = 7342573046357
Nagios Web = 5323572.80B
How the plugin estimate these values on the Nagios web interface?
Thanks in advance.
First of all, I want to congratulate you on your excellent work with this plugin!
I have a question, I don't understand at all how are obtained the net statistics...
If I check TxBytes in /proc/net/dev to review statistics for bond0, I watch a large number in bytes: 7342573046357
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
bond0:1259548428146 14687025821 0 0 0 0 0 0 7342573046357 15194696711 0 0 0 0 0 0
But, If I check the Nagios web interface, this amount doesn't match with the previous value:
/proc/net/dev = 7342573046357
Nagios Web = 5323572.80B
How the plugin estimate these values on the Nagios web interface?
Thanks in advance.
byfeisar, September 29, 2014
Hi,
Thanks for the great plugin. If NFS mounts on the system are unresponsive then an unrelated disk check using this plugin times out.
Can this be fixed?
Thanks for the great plugin. If NFS mounts on the system are unresponsive then an unrelated disk check using this plugin times out.
Can this be fixed?
Page 1 of 3




